今天带来两道图论的题目:547. 省份数量 , 797. 所有可能的路径
547.省份数量 题目描述:
有 n 个城市,其中一些彼此相连,另一些没有相连。如果城市 a 与城市 b 直接相连,且城市 b 与城市 c 直接相连,那么城市 a 与城市 c 间接相连。
省份 是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个 n x n 的矩阵 isConnected ,其中 isConnected[i][j] = 1 表示第 i 个城市和第 j 个城市直接相连,而 isConnected[i][j] = 0 表示二者不直接相连。
返回矩阵中 省份 的数量。
示例:
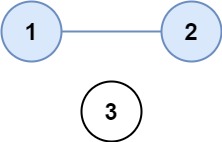
输入:isConnected = [[1,1,0],[1,1,0],[0,0,1]] 输出:2
本题不算很难,但是因为是没有接触过的类型,整体会觉得很陌生,应该多练几题熟悉一下应该就会渐渐懂了。
本题需要使用到并查集,在c++中我们一般使用哈希表来当做并查集。
并查集和树比较类似,树每个节点会记录其子节点,而并查集会记录其父节点。
在这道题目中我们可以把相连的城市在并查集中相连接起来,储存方式是当前节点与其父亲的键值对。
unordered_map<int, int> father;void add(int x){
if (!father.count(x)){
father[x] = -1;
nums++;
}
}每次有单独城市的省份出现计数nums就可以加一,之后连接时再减一即可。
在连接函数中,如果我们发现两个节点相通,也就是他们的祖先应该是相通的,我们需要再通过另一个find函数来寻找两个相通节点的祖先节点,如祖先节点相同即可合并连接。
void merge(int x,int y){
int root_x = find(x);
int root_y = find(y);
if (root_x != root_y){
father[root_x] = root_y;
nums--;
}
}find函数也比较简单,不断向上遍历父节点即可找到祖先节点了。
int root = x;
while (father[root] != -1){
root = father[root];
}但是还是有可以优化的地方,如果我们的树很深的话,需要遍历很多次才能找到祖先节点,我们可以将一条树上所有节点的父节点全都指向祖先节点,以实现路径压缩使查找时间缩短。
while (x != root){
int original_father = father[x];
father[x] = root;
x = original_father;
}注意前面已经遍历过一遍x,已经查找到祖先节点就为root。
这样最主要的三个函数就完成了,只需要在主函数中遍历每个节点将其加入并查集中,再按照isConnected数组中的连接情况来合并连接即可。
class UnionFinde{
public:
int find(int x){
int root = x;
while (father[root] != -1){
root = father[root];
}
while (x != root){
int original_father = father[x];
father[x] = root;
x = original_father;
}
return root;
}
void merge(int x,int y){
int root_x = find(x);
int root_y = find(y);
if (root_x != root_y){
father[root_x] = root_y;
nums--;
}
}
void add(int x){
if (!father.count(x)){
father[x] = -1;
nums++;
}
}
int get_nums(){
return nums;
}
private:
unordered_map<int, int> father;
int nums = 0;
};
class Solution {
public:
int findCircleNum(vector<vector<int>>& isConnected) {
UnionFinde uf;
for (int i = 0; i < isConnected.size(); i++){
uf.add(i);
for (int j = 0; j < i; j++){
if (isConnected[i][j]){
uf.merge(i, j);
}
}
}
return uf.get_nums();
}
};797.所有可能得路径 题目描述:
给你一个有 n 个节点的 有向无环图(DAG),请你找出所有从节点 0 到节点 n-1 的路径并输出(不要求按特定顺序)
graph[i] 是一个从节点 i 可以访问的所有节点的列表(即从节点 i 到节点 graph[i][j]存在一条有向边)。
示例:

输入:graph = [[1,2],[3],[3],[]] 输出:[[0,1,3],[0,2,3]] 解释:有两条路径 0 -> 1 -> 3 和 0 -> 2 -> 3
本题主要考察的还是深度优先遍历dfs的应用,也算是回溯算法的应用。
回溯算法主要的步骤就是:
1.确定终止条件;
2.递归运算;
3.回溯(返回到递归之前的状态)。
本题的终止条件很明显,就是要找到节点n – 1,只要递归到n – 1即可return
与以往做的回溯算法不太一样的是,这次要在数组表示的有向图上面进行遍历,所以我们首先要明确好这个递归的参数。graph[0]代表的就是节点0能够到达的节点,我们向graph[0]中的元素继续向下递归即可。这样一来我们可以将递归的参数决定为,这个graph数组以及其下标。
结果的储存我们需要用到一个二维数组result,还有一个记录路径的一维数组path,每次遍历到n – 1节点时就可以将path数组加入到result中了
vector<vector<int>> result;
vector<int> path;
void backtracking(vector<vector<int>>& g, int x){
if (x == g.size() - 1){//遍历到n - 1节点
result.push_back(path);
return;
}
for (int i = 0; i < g[x].size(); i++){
path.push_back(g[x][i]);
backtracking(g, g[x][i]);
path.pop_back();//进行回溯
}
}这个回溯的操作在一开始接触时,会因为陌生而比较难以理解,就像上一题的并查集一样,但多训练几题就会比较清晰的感受到了。
最后就是调用回溯函数计算即可
vector<vector<int>> allPathsSourceTarget(vector<vector<int>>& graph) {
path.push_back(0);
backtracking(graph, 0);
return result;
}今天其实还做了一道比较难的Dijkstra算法的题目,但感觉太难,要是今晚也写进来的话,又要写到很晚了,我感觉写日志这种事最好还是不要全堆到晚上的一整块时间来写,这样的话如果一写写太多了就消耗太长时间了,而且还影响休息。最好还是能够抽出零碎的时间来写写,但有时候就是到中午还没怎么刷题,零碎的时间也拿来玩手机了,所以现在留那么一道题,先消化消化,到明天再拿零碎的时间来写到日志里来。虽然一口气写完后可以听着网站放的小曲,惬意地看看自己的网站里自己写的东西,但为了不影响休息还是抽零碎时间来写吧。
